- 株式会社オールアバウト
- システム部 開発1グループ
- 大原 和人
エラーの可視化でエンジニアの意識が変わる 月間1億PV超のAll Aboutを支える仕組み

今回のソリューション:【fluentd/フルエントディー】
Webサービスやアプリの運営会社では、その開発に注力するあまりシステムの運用や開発プロセスの効率化には手が回っていないというケースも多い。サービスが日々成長していく中では、明示的に時間を確保しなければ業務改善の取り組みを続けることはどうしても難しくなる。
その問題に対し、総合情報サイト「All About」を運営する株式会社オールアバウトでは、「新しい技術を学んで業務を効率化する」というミッションを背負った若手中心のチームを立ち上げた。
そのチーム「Team TechBall」のメンバーは、業務時間の20%を使って日々システムやプロセスの改善に取り組んでいる。今回はその数ある活動の中のひとつ、fluentd、Elasticsearch、Kibanaを活用したログ監視のシステムについて、同社でエンジニアを務める大原 和人さんにお話を伺った。
新卒で1億6千万PVのサイトを支えるインフラチームに配属
私は新卒でオールアバウトに入社し、今年で4年目になります。それまでは大学院では動画圧縮の研究をしていたのですが、数年先のための研究より、もっと今の世の中に近いものに携わりたいという想いがありました。
そこで研究者の道ではなく就職することを決め、以前から興味を持っていたWebメディアの世界に進みました。
弊社には今エンジニアが30人程おりますが、そのうちサービスの開発チームに20人、インフラチームに5人、残り5人がデータ集計システムを作っています。
私は開発チームに行きたかったのですが、「最初にインフラを経験しておけば後々役に立つから!」という口車に乗せられて(笑)、インフラチームに参加することになりました。

当時、弊社のサイトは月間で1億6千万PVほどのアクセスがあったのですが、インフラチームは2人でそれを支えていたんです。
そこでデータセンターのハードウェアの設置からネットワークの構築、ミドルウェアの構成まで、色々と担当させていただきました。結構大変で、最初の頃は毎晩起こされたり(笑)。
ただ色々なことに興味がありましたし、非常に良い経験ができたな、と思っています。3年間インフラを担当した後、今では開発チームに移ってサービスの運用やエンハンスを行っています。
インフラ・開発チーム合同でシステム改善プロジェクトが発足
インフラチームに配属されて2年目の頃、技術的負債や運用効率の悪さを改善していく若手中心のプロジェクトが立ち上がりました。
開発チームも混ぜた「Team TechBall 」というチームを作り、業務時間の20%を使ってシステムやプロセスを改善していこうという取り組みです。
弊社ロゴの赤い丸の部分が「RedBall」と呼ばれていることが、チーム名の由来になります。そのプロジェクトで、Jenkinsを使ったデプロイ自動化やテストの導入、SVNを使って管理していたソースコードをBitbucketに移すといった業務の効率化を進めていきました。
その一環として行ったのが、エラー監視システムの見直しです。当時はエラー通知を全部メールで飛ばしていたので、緊急性の高いものもそれ以外も一緒の扱いになっていて。
件数も多く1日100通を超えることもあったので、どうしてもエラーメールをしっかりと確認する習慣が出来なかったんです。
Gmailのフィルターを活用して頑張ってフィルタリングしている人もいましたが(笑)。そこでしっかりとエラー監視の仕組みを作ろうということで取り入れたのが、fluentd、Elasticsearch、Kibanaの組み合わせです。
エラー監視をする場合には、NewRelicのようなクラウド型サービスを使うのも良いと思います。ただ、この組み合わせであればオープンソースなのでコストはかかりませんし、導入も簡単で、かつプラグインが充実しているのでカスタマイズも容易です。このような理由から、今回の構成を選びました。
ログの転送にはfluentdを活用 豊富なプラグインが魅力
実際にどのような用途で活用しているかと言うと、アクセスログの解析です。例えば弊社のサイトだとページ数が大量なので、どこのページでリンク切れが起きているのかを手動でチェックすることは難しいんですね。
そこでfluentdでアクセスログを収集して転送し、Elasticsearchからログ名とステータスコードを指定してクエリをかけて、404エラーがどのパスで起きているのかということを可視化しています。
####▼様々なログを収集し、転送するfluentd
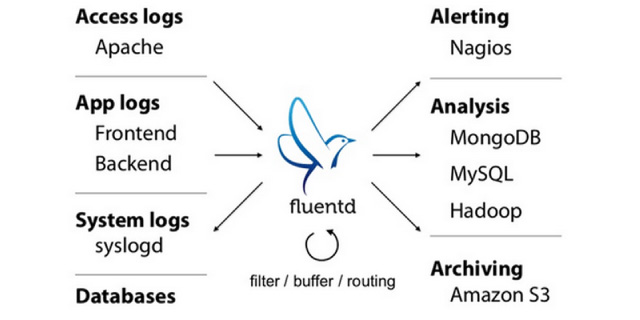
ログを収集する部分にfluentdを使っているのですが、最近ではEmbulkというツールもありますね。
まとめてデータを転送するにはEmbulk、リアルタイムに処理をするにはfluentdという使い分けが主流かと思います。どちらもプラグインの開発が活発で、拡張性が高い点が魅力ですね。
fluentdの導入前は、自前でスクリプトを書いてログを転送していました。ただこの場合、失敗した時の再送処理など、正確に動かすためには配慮しなければならない点が多いんです。
その面倒な部分を、簡単な設定をするだけで担ってくれるのがfluentdなんですね。
fluentdを経由して、エラーログだけではなくアクセスログもElasticsearchに転送しています。ただアクセスログを全て転送するとElasticsearchが詰まってしまうので、fluentdで適度にサンプリングしている形です。このような処理もプラグインで簡単に実現できます。
エラーの発生状況をKibanaのダッシュボード上で可視化
更に、発生しているエラーに関してはすべてKibanaのダッシュボード上に可視化しています。アプリケーションごとにどのページで、どのエラーが何件起きているかを確認することができます。
そうすることで、「昨日のリリースでパフォーマンス悪くなったね」といった話も出来るようになりました。
▼Kibanaのダッシュボードにエラーの発生状況を可視化
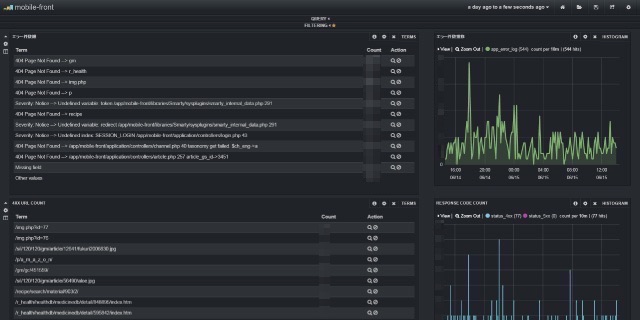
また、Kibanaではエラー件数毎にランキングでの表示が可能なので、対応の優先順位がつけやすくなりましたね。このランキングに関しては、PHPで簡単なプログラムを書いて毎日担当者にメールでも通知されるようにしました。
メールのタイトルにエラー件数が表示される形にしているので、メールの開封しなくても緊急度合いがわかるようになりましたね。
▼メールで担当者にエラー件数を自動で通知
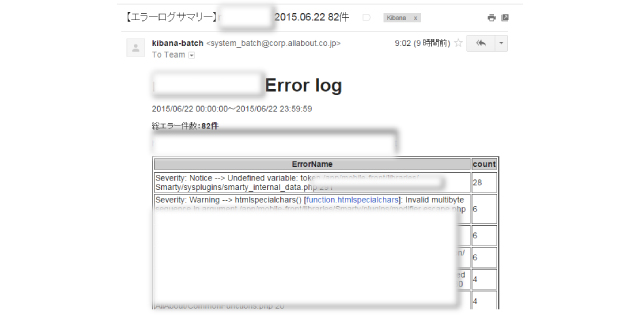
そして対応の抜け漏れがないように、発生した重大なエラーはGoogleスプレッドシートに自動的に記録される仕組みも作っています。また、少しでもバグ対応を楽しくするためにエラーに対応する人をくじ引きで決めてみたり(笑)、色々と工夫しています。
運用のコストは最小化し、クリエイティブな仕事に注力する環境を
監視システムを構築しエラーが可視化されたことで、エラーの発生件数を半年で10分の1にまで抑える事が出来ました。
404エラーのように、今まで発生箇所の特定までは出来ていなかったエラーが特定可能になったことも大きいですが、何より状況を可視化することによってメンバーが自発的にエラーに対応する文化が出来たことが大きいです。
▼半年間でエラー件数が10分の1に減少!

Team TechBall の方針として、「面白いから」ではなく、「ためになる」ことをしようと常に考えています。エラー監視を導入したときも、ただ可視化をするだけではなく実際にエラーを減らすにはどうしたらいいか、複数の技術がある中でどのツールを導入するのが一番いいのかを考えました。
こういったことを実現するためにも、半年に一回程度、どこにコストが一番かかっているかをブレストする場を設けています。
そこで例えばレビューに時間がかかっているという意見が出たら、レビューのガイドラインを作ったり、レビューツールを入れるといった対策を実施しています。

最終的に目指しているものは、できることは完全に効率化して、皆が空いた時間をサービスの開発に注力できるようにすることです。エンジニアは出来るだけ運用にかけるコストを減らして、クリエイティブな仕事をするべきだ、ということを今年の開発チームのテーマにしています。
これまでと同じレベルの成果をアウトプットし続けながらもそこに掛ける時間を減らし、新しいものを生み出していけるチームを作っていきたいですね。(了)