- Retty株式会社
- CTO
- 樽石 将人
Rettyに学ぶ 月間UUを1,500万に成長させた、誰もがビッグデータを扱える環境とは

今回のソリューション:「トレジャーデータサービス」
〜「直感頼み」のユーザー分析を「データドリブン」なものに変え、結果的にユーザー数を倍増させた「トレジャーデータ」活用法〜
日本最大級の実名型グルメサービス「Retty」は2015年5月に月間ユニークユーザー数1,000万人突破を達成し、現在では1,500万人を突破している。同サービスを運営するRetty株式会社は「食を通じて世界中の人をHappyに」を掲げ、何よりもユーザー体験を重視し、飽くなきUXの改善を繰り返している。
そんなRettyだが、実は2014年の後半にはユーザー数が500万人から伸びない、という壁にぶつかっていたのだという。そんな時に同社CTOの樽石 将人さんが行ったのは、データドリブンにPDCAを回していくための分析基盤を確立し、非エンジニアでも見たいデータをすぐに取り出せる環境を構築したことだった。
「誰もが使えるデータ分析基盤を必ず用意する必要がある」と語る樽石さんに、およそ半年間でのUUを倍増に一役買ったデータ環境の構築について聞いた。
Rettyの「ヒト目線」なビジョンに共感しジョイン
私は小学生の時からゲームを自分で作ったり、プログラミングに触れてきました。社会人として最初は、RedHatに入社し、組み込みシステムの開発やミドルウェアの開発・セールスエンジニアの業務に携わってきました。
その後Googleに転職し、4年間 SWE (Software Engineer) や SRE(Site Reliabillity Engineer)として、開発から運用まで様々なプロジェクトに関わりました。
東日本大震災が起こった時には、パーソンファインダーという、安否情報のための掲示板を作っていました。ハイチ地震の時に基盤は作ってあったのですがガラケー対応が必要で、結局ガラケー用に別途作ったんです。あの時は、無我夢中で必死でしたね。

最終的には「もっと役に立つものが作れたかもしれない」という、無念さのほうが大きかったと記憶しています。それがきっかけとなって、Googleを辞め、日本の企業を応援しようと転職して1年ほど経った時に、RettyのCEOに出会いました。
この出会いはミラクルでした(笑)。ヘッドハンティングの連絡が僕のFacebookメッセージに来ていたのですが、知らない人なのでスパムフォルダに入っていて。整理していた時に偶然見つけて、オフィスが家から近いこともあって遊びに行きました。
その時に聞いた「食を通じて、世界中の人々をHappyに」という人に向いたRettyのビジョンに共感して。Googleの時に存在していた、会社の在るべき形に非常に近くて、素敵だなと感じました。そういった背景で、2014年6月にRettyに入社しました。
100万→1,000万UUへ グロースを支えたデータ環境構築
僕が入社した頃、Rettyの月間UU数は100万人ほどでした。ユーザーがどんどん増えてきていて、システムをサービスがスケールできるような設計に変えていくタイミングでしたね。
最初は、スケール以前にユーザーが「このサービスいいよね」と思ってくれるUXを作り上げ、「お店口コミ投稿アプリ」としてのRettyを確立させることが最重要でした。
それを2年間続けて口コミデータが蓄積されたところで、そのデータを活用してサービスをより多くの人に使ってもらうフェーズに入りました。
結果的に2015年5月に月間UU数が1,000万人を超えたので、1年半という短期間で10倍にグロースができたことになります。ただ実は、ユーザー数が500万人を超えたタイミングで一度、伸び悩みに苦しんだ時期があったんですよね。
その転機になったのは、蓄積されたデータを誰でも深く分析できる環境を作ったことです。エンジニア以外のプランナーも見たい時に詳細なデータを引き出せるようになったことで、それまでの「直感頼み」だった改善がデータドリブンなものに変化しました。
結果的に、2014年11月には500万人前後で停滞していたユーザー数を、半年後に倍増させることができました。
UX改善のために必要なデータを集めるには、相応の基盤が必要
Rettyにおいてデータドリブンにスピード感を持ってUXを改善していくためには、外食産業における消費者の行動分析を行う必要があります。この分析は簡単ではなく、相応のデータ分析基盤が必要です。そしてそのデータは大きく分けて、飲食店に関するものと、消費者の外食需要に関するものになります。
飲食店に関するデータとは、国内の80万店舗に及ぶ店舗のメニューや座席数といった最新情報です。これらは、
- 一般消費者の方からの情報提供
- Rettyの調査隊による調査
- 食品・飲料メーカーなどを想定したデータフィードAPI
- 自然言語解析、画像認識等の計算機科学を応用したお店情報の高度データ化
といった手法を用いて構築しています。
また、飲食業界では毎年10万店舗が入れ替わると言われていますが、常に最新情報を持つために地道な作業を行っていたりもします。例えばRettyの飲食店調査チームは、一般の方が入力した店舗情報に誤りがないか、実際に見に行ったり、電話をかけてデータをフレッシュにしています。
消費者の外食需要に関するデータは、①PC、スマホ、Webユーザーの興味・行動、②アプリユーザの食生活ライフログとソーシャル情報、のふたつが中心です。
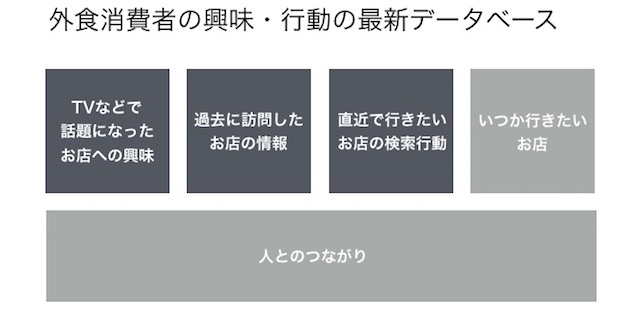
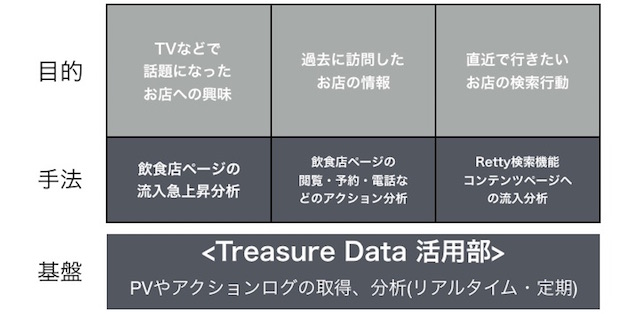
例えば「マスコミで話題になった◯◯という飲食店」がどれだけ消費者の興味を引いたかを調べるためには、飲食店ページへの流入の上昇具合を調べています。また、ユーザーが過去に訪問した店舗を把握したければ、過去のページでの閲覧・予約・電話などのアクションを分析します。
このように目的によって手法は異なりますが、その基盤にはPVやアクションログの取得・分析を実行できる環境を用意する必要があります。
トレジャーデータを活用し、扱いやすいデータベースを構成
データ分析基盤は、クラウド型ビッグデータ解析サービス「トレジャーデータ」を中心に構成しました。Rettyのアプリやブラウザから、トレジャーデータのオープンソースのソフトであるtd-agentでHTTPリクエストログをトレジャーデータに転送しています。
Webサーバーへのアクセスログをトレジャーデータに流しているのですが、Webサーバーへの負荷を減らすため、HTTPリクエストはまずキャッシュサーバーに辿り着く構造になっています。
キャッシュサーバーに目的のコンテンツがない場合のみ、Webサーバーにアクセスがいきます。但しこの場合、Webサーバーに到達しないリクエストのトラフィック取得ができなくなってしまうので、別途アクセスログを記録するために、Webサーバへ直接アクセスしています。
ログの取得設定は、エンジニアでなくても簡単にできるようになっています。例えばユーザーの「電話をかけました」というデータを取りたい時には以下の1行を書くだけで、ログを取得することができます。

取得したログについては、Rettyではトレジャーデータの中に、データのリアルタイム性、情報量などに応じた複数のデータベースを用意しています。まずは、リアルタイムDB。このDBにはtd-agentを通してリアルタイムにデータが蓄積されていきます。
次がhourly DBで、リアルタイムDBが1時間に1回処理をされます。そこから更にhourly DBが1日単位で移動されるdaily DB、それが1週間経過すると移動するweekly DBがあります。
用途に応じて3つのデータベースを用意
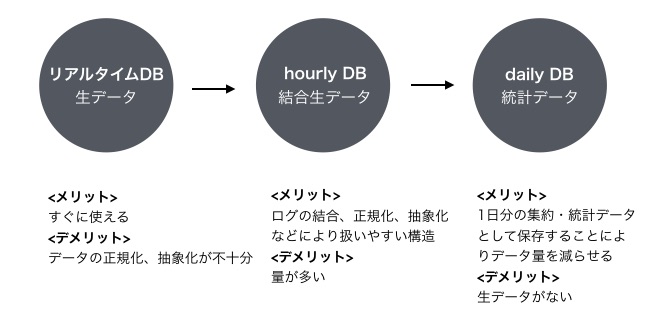
リアルタイムDBには、生データが入っています。即時性は高いのですが、生データなので加工がしづらい問題があります。hourly DBにはリアルタイム DBの生データを加工し、扱いやすい状態で置かれていますが、すべてのカラムを残した状態のためデータ量が大きく、Queryの期間を長くした分析をすると非常に時間がかかってしまいます。
そういった場合には、店舗に対する興味や行動を1日単位で集約して、統計データとして保存しているdaily DBを使用します。リアルタイムDBやhourly DBに比べるとデータ量は多くないので、長期間にわたる分析の際に短時間で結果を出力することができます。デメリットとしては、生データではないので、詳細な分析調査はできません。
KPIのチェックには主にdaily DBを使うことが多いですね。weekly DBのデータ量はdairyDBの7分の1なので、今後の運用でdairyDBのデータ量が圧迫されてきた場合などに使うかもしれません。
それぞれのDBの中には、様々なテーブルを作っています。リアルタイムDBには中に「event」というテーブルが入っていて、ユーザーの行動の生の情報が格納されます。これを1時間に1回処理するんですね。扱いやすい構造になって、hourly DBに溜まっていきます。

加工されたhourly DBのeventテーブルからユーザーの行動ごとのテーブルに分けていきます。ユーザーの電話や予約は「action」のテーブル、見たページについては「pageview」というテーブルに分けられていきます。
なおactionというテーブルはeventのテーブルが完成しないと実行できません。なので、テーブルを構成していく上では「これが終わったらこれを実行する」という順序立てた実行が必要になってきます。そのためにLinuxのcron/make/run-partsの3つのコマンドを使って、自動で実現していくようにしました。
直感からデータドリブンへ 半年でUU数が倍増!
このようにアーキテクチャを組むことで、アプリやブラウザの生データからトレジャーデータを使って簡単に分析できるようになります。そして分析結果も、Google スプレッドシートなどでグラフ化してシェアしています。
非エンジニアでもすぐに知りたいデータが出せるようになったことで、エンジニアに限らずみんながデータを見る習慣がついたことが一番の良い変化だと思います。
それまでは「こういうページにしたらいい『はず』だ」といった直感に近いものだったのが、今ではデータドリブンな提案をする方向に変わりました。それはユーザー数の伸びにも、結果として現れていると思います。
トレジャーデータは扱いやすく、30分くらいちょっと試しているうちに使えるようになりました。痒いところに手の届く関数も多くて、必要な分析をすぐに行えるのも良かったですね。
利用当初はサポートにもお世話になりました。コンソールを立ち上げるとすぐにチャットが開始できるので、おかしい部分をすぐに報告して調査してくれます。もちろん日本語で対応してくれますし。
導入後は僕が自らトレジャーデータを使って、「こんなことができるよ!」と見せているうちに、社内の口コミで自然に広がっていきました。データを何を使うのかという点にといて、みんなが使えるようにバトンを渡せたのが良かったと思います。
データ分析の環境に関しては、やはり誰もが使えるように設計を作り込み、うまくPDCAを実行する人に回せることが重要だと思います。今後もサービスのグロースに貢献していけるように、引き続き頑張っていきたいですね。(了)