- メディカル・データ・ビジョン株式会社
- 技術研究室 室長 シニアマネージャ
- 渡邉 幸広
1400万人超の医療ビッグデータ活用の基盤、Hadoopディストリビューション「MapR」とは

今回のソリューション:【MapR/マップアール】
〜Hadoopディストリビューションの「MapR」を導入し、分散していた医療データを集約させた事例〜
データを活用したビジネスが活発化している。その中でも、医療系データは、最も注目を集める分野の1つだ。
メディカル・データ・ビジョン株式会社(以下、MDV)は、いち早く医療データの活用を始めている企業のひとつ。医療機関向けにシステムを提供し、そこから得られるデータを活用したビジネスを展開している。
しかし、システムの開発を優先してきた結果、各システムが個別にデータを管理し、横断的に活用することが難しくなっていたという。
その状況に対して、Hadoopディストリビューションの「MapR(マップアール)」を中心としたシステムを構築し、統合的に使える基盤を構築したのが、技術研究室の渡邉 幸広さんと、高嶌 浩佐さん。
医療データという特殊な環境にMapRを導入した理由、そして医療データの今後まで、お二人にお話を伺った。
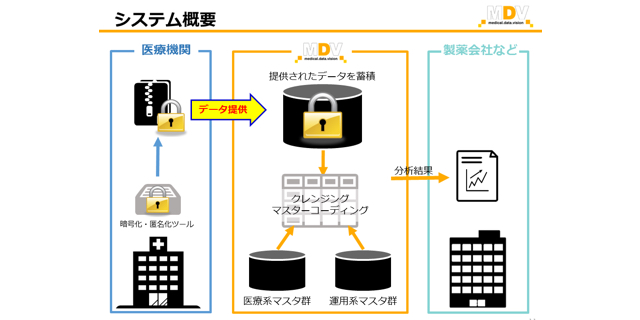
▼MDVでのデータの活用イメージ
医療データの活用を広げるため、技術研究室を立ちあげ
渡邉 私は、今までのキャリアで一貫して、データ関連の仕事をしていました。基幹システムのデータベースの物理・論理設計や、飲食店検索サイトのデータをどう効率よく管理して、サービスに適用するかというところを担当していました。

弊社は、医療データを大量に扱いながら、順調に成長してきています。2016年6月時点では、1,470万人分、国民の9人に1人に相当する規模の医療データを扱っています。
今後さらにデータの利用先を増やしていくため、基盤をしっかりと構築し、ビジネスが加速できる環境を準備する必要がありました。そうした中で縁あってお誘いいただき、2015年6月に入社すると同時に技術研究室を立ちあげました。
高嶌 私はもともと関西のSIベンダーで、Web系の開発をしていました。2007年ごろ、当時一緒に仕事をしていた人たちと東京に出てきて働いていましたが、所属していた会社が営業部門だけを残して撤退することになりました。
そこで転職活動を始めて、社会に貢献できる医療業界に惹かれて2009年にMDVに入社しました。

入社後は研究開発部(現システム開発部)という部署にいたのですが、そこでは研究ではなく開発を中心に行っていました。そこで得た医療システムの開発ノウハウを活かすために、渡邉が立ち上げた技術研究室に異動しました。
事業間でデータを共有し、更なる成長を目指す
渡邉 弊社は、DPC対象病院(※入院医療費の定額支払い制度を導入している病院)に経営分析の支援システムを提供しています。
そこで2次利用の許諾を得たデータを収集・蓄積し、これまで把握することが困難だった臨床現場の医療実態を、分析データとして製薬企業や研究機関に提供しています。
提供したデータは、製品開発やマーケティング戦略の立案、研究論文のエビデンスとして活用されています。
経営分析システムの提供、分析データ提供という主に2つの事業を展開していますが、それぞれの事業が個別に成長してきたため、データの取り扱いがパッケージごとに異なっていました。
今のビジネスを続けていく分には問題無いですが、まだ見ぬ新規事業を始めるために、データを活用しやすい環境を根本から作っていく必要がありました。
そのために、データを中央で集中的に管理できる基盤の開発を、技術研究室で進めています。
Hadoopディストリビューションの「MapR」を選択
渡邉 まず初めに、私が全体の構成や機能配置といったアーキテクチャを決め、それから高嶌が実際にサーバーを構築したり、プログラムを書いて回したりするところを担当しました。

高嶌 渡邉が一般的なビッグデータのソリューションを組み合わせて全体像を作り、そこに私が医療データの知識を入れていく、という作業を行いました。渡邉がソリューションを提案し、将来的に必要となる可能性がある場合には仕様を検討し、医療データを扱う上で無理・無駄のない全体像を具現化させていきました。
渡邉 今回構築したシステムの中でも、ファイルシステムの部分にHadoopのディストリビューションであるMapRを導入しました。以前からMapRの特徴はよく知っていたので、今回の要件に合うと考えました。
「医療データ」という特殊な環境に活きる特徴
渡邉 DPC対象病院は、自院の診療報酬を定型化されたフォーマットで厚生労働省に提出する必要があります。
例えば、「様式1」というフォームには患者の性別や生年月日、病名などの診療録情報が記載されており、「E・Fファイル」というフォームには、データ識別番号や、データ区分(手術、検査、処方などの診療区分に対応)に関する項目が記載されています。
このように、一つ一つのテキストファイルは小さいのですが、数は膨大になります。
このような膨大で多様なデータを扱うには、単純なストレージとして効率よく扱えるMapRが最適でした。病院から来たファイルを、ストレージにコピーする感覚で扱えるというのがメリットです。
OSSのHadoopなら、PUTやGETで操作したり、Write Onceのため書き換えるにはもう1度書かないといけなかったり、普通のファイルと同じようには扱えません。MapRなら、コピーも削除もできるので、テキストファイルが多い環境においては有効です。
計算が必要な場合にも、MapR上で大量のデータを分散・並列処理ができます。今回は、計算機能とストレージの両面で検討した結果、MapRが最適でした。
コストは下がり、今後のスケールにも対応できる
渡邉 各パッケージがそれぞれ持っていたデータを一箇所に集約することで、サーバーのコストはトータルで下がると考えています。また、分散していた作業が一元管理されるので、業務も効率化されます。
パフォーマンスの面で言うと、細かいファイルが多い上、すべての機能を構築しきれていないため元々のデータウェアハウスに比べてもそれほど変わりません。ただ、今後データ量が増えていってもリニアに遅くなることはないので、効果が出ていくのはこれからだと思います。
今後データの種類が増えていくと、メリットは大きくなります。昨年から、患者から同意を得た診療情報を蓄積しているのですが、そういった非構造データはRDBで計算するのが難しく、MapRのようなシステムが活きてきます。
患者が自分の体を理解した上で、医療と向き合えるようデータ活用
渡邉 構想が始まってから5ヶ月、やっとデータセットの移行も終わり、第1フェーズが終わったというところです。今後はApache Sparkの組み込みや、AIの活用可能性を検討する必要があると思います。

高嶌 そうしたことを見越して、今は暗号化やAIの勉強会やセミナーに参加しています。新しい技術もたくさん出てきているので、細かい構成は変化を続けていくと考えています。
渡邉 今後弊社が扱うデータが増えていくと、病院を利用する患者へのメリットも大きくなっていきます。例えば、昨年医師と患者が診療情報を共有できる「カルテコ」というサービスをリリースしました。
患者が自身の診療情報を手元に持つことで、診療へ積極的に参加してもらいやすくなります。また、患者と医療従事者の間に、強固な信頼関係を構築することにもつながります。なお、医療の質を向上していく上でも、患者さんが自分の体のことを理解した上で、病院や診察、先生との話に向き合えるというのは、重要です。
そうした点を後押しするような取り組みを、データを活用することで進めていきたいです。
データの収集・蓄積と活用を繰り返すことで、医療業界の中で再びデータが回り、医療自体の質が向上していくような環境を私たちが作れたらな、と思っています。(了)