
- 株式会社白ヤギコーポレーション
- データサイエンティスト
- 堅田 洋資
世界のデータサイエンティストが集う「Kaggle」とは?ビッグデータ分析を競い合え!

今回のソリューション:【Kaggle(カグル)】
〜日本人の参加者に聞く!世界中のデータサイエンティストが競い合うコミュニティ「Kaggle」を解説〜
世界中から40万人を超える「データサイエンティスト」が集まる場所が、「Kaggle(カグル)」だ。
Kaggleは企業と、データ分析のプロであるデータサイエンティストをつなぐプラットフォームだ。企業がコンペ形式で課題を提示し、賞金の提供と引き換えに最も精度の高い分析モデルを得る。ある種クラウドソーシングに近い仕組みである。
世界規模で見ると、Amazon、Facebook、Walmartといった名だたる企業がコンペを実施しているKaggle。
日本ではまだまだ知名度は低いが、2015年7月には日本で初めて株式会社リクルートホールディングスがデータ予測コンペティション「RECRUIT Challenge – Coupon Purchase Prediction」を共催するなど、徐々に認知が拡大している。
今やあらゆる業界で「データ」の重要性が高まり、ビッグデータと呼ばれる大量の数値データを分析し、ビジネス戦略に活かすことは当たり前になった。そしてそれに伴い、データサイエンティストという職種のニーズも高まっている。
ビッグデータ・テクノロジーのエキスパートで、ニュースアプリ「カメリオ」を運営する株式会社白ヤギコーポレーション。同社でデータサイエンティストを務める堅田 洋資さんは、サンフランシスコ大学に留学していた時からKaggleを活用し、データサイエンスのスキルを高めてきた。Kaggleを通じて、Walmartからリクルーティングの声がかかったこともあったと言う。
今でも情報収集の手段として引き続きKaggleを使っているという堅田さんに、詳しいお話を聞いた。
▼世界中の企業がコンペティションを主催する「Kaggle」

データ分析の楽しさは、自分の中でPDCAを回す過程にある
2015年の4月に、データサイエンティストとして白ヤギコーポレーションに入社しました。弊社は、独自のアルゴリズムを使ったニュースアプリ「カメリオ」を運営しています。
私の担当業務としてはデータ分析になるのですが、ユーザーテストや、定性調査にも取り組んでいます。具体例で言うと、プッシュ通知の開封率を上げるために、機械学習のアルゴリズムを使って現状の問題点を洗い出して改善施策につなげる、といったことが業務になりますね。
プッシュ通知に関しては、以前は朝と夜に「新着記事があります」という定型文を送り、さらにマニュアルで「今日はドローンの記事があります」という形の通知を全員に流していました。でもこの場合、ドローンに興味がある人しか開封しませんよね。
そこでユーザーをクラスタリングして、各クラスタの中でよく読まれているジャンルの記事を自動的にピックアップして流すようにしました。そうすることで開封率は、2倍〜3倍に改善しました。
このユーザーのクラスタリングの部分にデータ分析の技術を使うのですが、カメリオの良いところは、ユーザー自身が自分の好きなテーマをフォローしていることです。その人が「これに興味があります」と言っている状態なので、これはすごく貴重なデータになります。

データ分析は好きですし、面白いですよ。その理由のひとつは、分析って仮説検証の繰り返しなんです。自分の中で「こうかな」と思って分析をしてみて、それが違っていたら、また考え直して別の方法で分析をしていく。自分の中でPDCAを回しているんですよね。そうしているうちに、だんだん本当の姿が見えてくるんです。この思考する過程が一番楽しいところかな、と思います。
算数が大の苦手だった 偏差値20からデータサイエンティストに
データ分析に初めて関わったのは、大学生の時です。その後、社会人経験を経てサンフランシスコ大学でデータサイエンスの修士号を取得し、今に至ります。
実は、もともと算数が得意だったわけでは全くないんですよ。高校2年生までは、偏差値で言うと20くらいだったんじゃないかと思います(笑)。
ある時から、急に数学が得意になったんです。それまでは、記憶力で算数や数学を解こうとしていたんです。でも公式が覚えられなくて…。
でもある時、通っていた河合塾の先生が、覚えられないのならば自分で公式を作っちゃおうと。平方や三角定理の仕組みをある程度理解しておけば、何があっても公式を導ける。それを理解した時から成績が伸びて、数学がすごく楽しくなったんです。
大学は商学部に進んで統計学を勉強し、ゼミもデータサイエンスを選びました。ただ当時はまだビッグデータという言葉もなかったので、データ分析ができる仕事は調査系くらいしかなくて。結果的に最初は、ファイナンスの方向に進み、いくつかの企業で経験を積みました。
サンフランシスコ大学で、データサイエンスの修士号を獲得
新規事業に2年関わって軌道に乗せたタイミングで、ある種の達成感もあったので、もう一度勉強しようと。そこでサンフランシスコ大学に留学して、データサイエンスの修士を取得することを決めました。ビッグデータという新しい言葉も出てきたので、改めて学ぶのもいいのではないかと。
サンフランシスコ大学のコースは、座学は週に3.5日。あとは週に1.5日、実際に企業でインターンをしながら、コースワークを終了させれば卒業できるというものでした。私の場合は、Williams-Sonomaという、カタログマーケティングが伝統的に強い高級家具の百貨店でお世話になりました。マーケティングアナリティクスのチームがあったので、働きやすかったですね。
単純に、サンフランシスコはすごく面白かったですよ。地元のシリコンバレーのスタートアップの人が講義に来てくれたり、なかなかない体験ですよね。
パートタイムの先生では、Googleで働いていた人もいました。実務レベルの話をたくさん聞けたので、本当に選んで良かったなって思います。本当にサンフランシスコ大学、誰か留学しませんか?(笑)私の後に日本人がいないようなのですが、心からオススメですよ。
企業とデータサイエンティストをつなぐ「Kaggle」に参加
サンフランシスコにいた時に使うようになったのが、「Kaggle(カグル)」です。Kaggleは、企業とデータサイエンティストをつなぐ新しい仕組みです。
企業や研究者がコンペ形式で課題を提示し、世界中のデータサイエンティストがチームや個人でその最適モデルを競い合います。コンペの順位に応じてポイントが付与され、ランキングとして反映される感じです。
▼世界中のデータサイエンティストが参加し、ランク付けされる
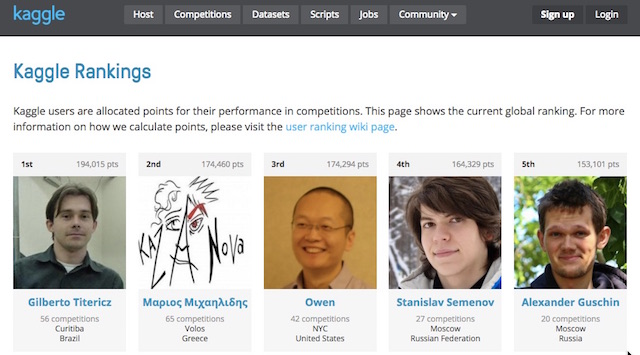
実際にデータサイエンティスト同士が何を競い合っているのかというと、予測の精度です。例えば、とあるファストフードチェーンのコンペの内容は、137店舗分だけの売上データを開示した上で、それを元に100,000店舗分の売上を予測するというものでした。
既に答えは用意されていて、運営側だけがそれを知っている状態です。我々が予測データをCSVで提出すると、自動的に答え合わせがされ、その精度に応じてスコアが付与されてランキングに反映されます。
分析に使うツールや手法は問われないのですが、もしコンペに勝った場合にはモデルを開示するという条件があります。賞金でそれを売り渡す、という形なので、一種のクラウドソーシングのような仕組みなんですよね。
学んだことを実務に活かせ、就職活動にも使えるKaggle
Kaggleは日本ではまだそこまでメジャーではないかと思うのですが、向こうではかなり流行っています。参加は、チームでも個人でも可能です。私は最初、大学で「みんなやるよね」という感じで登録しました。初めてコンペに参加したのは、マイクロソフトの会議室をお借りして実施された24時間耐久ハッカソンの時です。
データ分析ができる人が集まって、2チームに分かれてコンペに参加しました。そもそも参加した理由はタダでピザが食べられるからだったのですが(笑)、チームワークで挑める感じがすごく楽しかったですね。その後は、個人で参加するようになりました。
参加者のモチベーションとしては、まずはランキングがあるかと思います。それから就活ですね。Kaggleで実績があると有利ですし、コンペで上位に入ると企業から直接声がかかることもあります。
例えば、私が個人で参加したコンペティションのひとつに、Walmartの売上予測がありました。結果的には上位25%くらいでしたが、Walmartのリクルーターから「うちに興味ないですか」って電話がかかってきたんですよ。こんな風に、企業側は採用にKaggleを活かしています。
▼現在(2016年1月19日)開催中のairbnbのコンペティション
個人的には、大学で学んだことを活かせる、ということも大きかったです。学ぶのはあくまで理論で、実務に活かす場所はインターンしかなかったわけです。
でもそれだとやはりもったいないですし、自分のスキルにはしづらいので。Kaggleであれば実際のデータを使って分析ができて、結果が出れば就職できるかもしれないし,
自分の知見になるかもしれない。そこがモチベーションでしたね。
現在は最新の知識や手法をキャッチアップするために活用中
そういった理由から、学生時代はKaggleのコンペにはよく参加していました。ただ今はなかなかじっくり取り組める時間はなくて…。でも友人とたまに集まって一緒にKaggleを見て、情報交換的に活用しています。
Kaggleには掲示板があって、世界中からデータサイエンティストが集まっています。 ソースコードは公開できないのですが、皆でヒントを出しあったりするんですね。それを見ていると流行りの手法でああったり、新しいアルゴリズムを知ることができます。
そのような新しい情報にきちんとキャッチアップするために、今は使っているという感じです。
データの裏で巻き起こっている事実を想像することが重要

データサイエンティストに向いているのは、想像力豊かな人だと思います。データの裏で巻き起こっている、ユーザーの行動や記憶を想像できる人には面白いのではないでしょうか。あとは、分析結果を人に見せる時に、どう見えるかというアウトプットにこだわれる人ですね。
サンフランシスコでもよく言われたのですが、必ず線か棒グラフで、誰でも分かる形でアウトプットをすること。そしてアルゴリズムの責任には絶対にしないこと、それが大事だと。
私もインターン先で失敗したことがあって。難しいアルゴリズムを使って、こういうことができますよ、と見せたら「それって結局何がtakeaway(成果)なの」と言われてしまって。結局は、たとえ社内であっても見せるべき相手に伝わらなければ意味がないんですよね。
そういった部分を面倒くさがらずに、しっかり相手に分かりやすいアウトプットを出せる人は、データサイエンティストとして楽しんで仕事ができると思います。(了)
「マネジメントを効率化したい」というマネージャーの方へ
当媒体SELECKでは、これまで500社以上の課題解決の事例を発信してきました。
その取材を通して、目標を達成し続けるチームは「振り返りからの改善が習慣化している」という傾向を発見しました。
そこで「振り返りからの改善」をbotがサポートする「Wistant(ウィスタント)」というツールを開発しました。
「目標達成するチーム」を作りたいとお考えの経営者・マネージャーの方は、ぜひ、チェックしてみてください。






