- コラボレーター
- seleck
データは扱い方がすべて データドリブン開発5つのポイント

取材をしていると「データドリブンで開発をしています」という話をよく聞きます。一方で「データドリブンって一体何なの?」という疑問がある人も多いと感じます。そこで今回は、データドリブン開発を行うための5のポイントをまとめました。
※アジャイル開発が前提となります。
データドリブンって何?
効果測定などから得たデータを元に次の行動を決めることです。WEBやアプリの開発においては、何かの機能を実装したあとに、必ず効果を測定し、次の開発に生かします。
データドリブンの開発フロー
データドリブンで開発をうまく回している企業の話を整理すると、データドリブンの開発は下記の1〜5をグルグルと繰り返します。
1.仮説立案
まずは「どのような機能を実装すれば良いか」という仮説をブレーンストーミングでとにかくあげていきます。ユーザーからの声や自分で使ってみて感じたことでもなんでも上げてためておく企業が多いようです。

2.優先順位付け
あがってきた仮説に優先順位をつけます。開発スタイルにもよりますが、プロダクトオーナーと呼ばれる人が、インパクトと開発工数の掛け算で優先順位を決めていくパターンが多いようです。

3.狙いの言語化
実際に実装する項目が決まったら、「狙い」を言語化することが重要です。「その機能を作ることで何を実現したいのか」ということをなるべく目標数値とあわせて言語化しましょう。

例えば、ファッション系のアプリで「おすすめを表示する」という機能を実装する際に「登録した初日に興味ジャンルをフォローするユーザーを20%増やしたい」という狙いを定義し、言語化することが重要です。
4.機能の実装・リリース
上の「狙い」が実現できたかをデータで効果検証ができるように機能を実装しリリースします。

5.分析・解釈
リリースして一定期間経った時点で、「狙い」が実現できたかをデータで判断します。先ほどの例だと「登録した初日にフォローしたユーザーの数が20%増えたか」ということをデータで見て、増えてなければ「なぜ増えてないのか」を解釈します。

その後は1に戻ってフローを繰り返します。
データドリブンのポイント①:プロセスが重要
データドリブンの開発は、効果を測定しその次に生かしていくことがポイントです。そのため、実装した結果も重要ですが、それ以上にプロセスをいかに早く回していくかが重要になります。

機能を実装した結果、狙い通りにならなくてもそこでの学習が次につながれば、すべての実装が財産になります。手を動かすエンジニアやデザイナーのストレスも減るのではないでしょうか。
データドリブンのポイント②:解釈や仮説のためにユーザーテストは有効
効果測定をして狙い通りになっていないことが分かった時に「なぜそうなったのか」という解釈をする必要がありますが、解釈の第一歩は疑うことです。
例えば、あるアプリケーションで「おすすめ機能を実装すればユーザーがフォローする数が増えるはずだ」という狙いを立てて、おすすめ機能を実装したにも関わらず「ユーザーがフォローする数が増えていない」ということが分かったとします。
この時に、なぜ狙い通りに行かないのかを解釈するためには、ユーザーテストを実施するのが一番早いです。
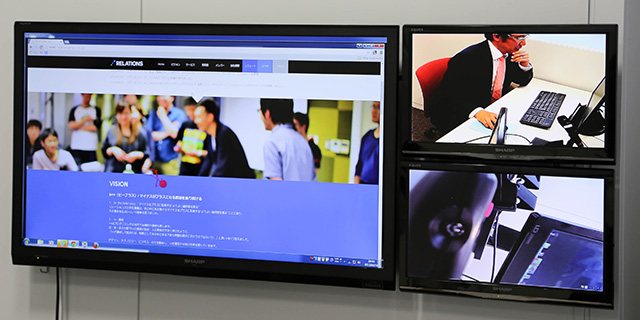
ユーザーテストとは、実際にユーザーがサービスを使っている姿を見て分析をする手法です。実際に質問ができるので「おすすめ機能をなぜ使わなかったのか」という質問をすれば、必ず解釈のヒントが得られます。
ユーザーテストを解説した記事はこちら↓
ユーザーの声、本当に拾えてる?ユーザーテストの重要性と3つの実践方法
例えば「オススメ機能に気付かなかった」といった声が拾えれば、そもそも「オススメ機能が気づかれていないかもしれない」ということを疑えるので、データで検証すれば良いだけになります。
また、「オススメ機能が気づかれていない」という解釈が得られた結果、「どうすればオススメ機能を見るようになるか」という仮説についても、ユーザーに直接聞けばヒントを得ることができます。
簡単なペーパープロトタイプを作って「これだったら気づきますか?」といったことも確認できます。
データドリブンのポイント③:解釈や仮説をデータから導くならミクロデータを見る
解釈や仮説を導き出すためにはユーザーテストが有効ですが、毎回行うのは大変です。ユーザーテストから解釈や仮説が導かれるのは、要するに「具体的な情報を取得できるから」なので、データ分析でミクロなデータを見ることで解釈や仮説を導くことができます。

例えば、ユーザー全体のアクティブ率が伸びない時に、ユーザーを細かく切って分析をしてみます。アクティブになっているユーザーと登録してすぐに使わなくなってしまったユーザーに分けて、それぞれを細かく分析していきます。
すると、「アクティブになっているユーザーは登録初日に、5つ以上のジャンルをフォローしており、使わなくなってしまったユーザーは登録初日に、平均で1つしかフォローしていない。」という結果が見られるかもしれません。
そうなれば「登録初日にフォローさせることでアクティブ率が伸びるはずだ」という仮説を得ることができます。ミクロなユーザーの動きをデータで追えば、解釈や仮説を出しやすくなります。
徹底的にデータドリブンな開発をしているSumallyのデータ解析を担当する日下部さんは下記のように話しています。

サービス成長のカギはミクロなユーザー分析!「仮説を生む」データの使い方とは
あとWebのデータ分析で重要なことは、1人ひとりのユーザーの動きをなるべく細かく見ることだと思います。使ってくださっているユーザーは人間なので「KPIがこう動いた」というマクロの動きを見るだけでは捉えることができず、改善のアイデアを出すことが難しいんです。
例えば「今月はあるKPIが5%下がりました」というマクロなデータだけでは、「なぜそれが起こったのか。どう改善したらいいのか」という次の施策につながる仮説は生まれません。「今月は正月だったので忙しかったんではないでしょうか」みたいな話になってしまう。
一方で、マクロな動きに加え、ミクロな動きも見ていけば、施策につながる仮説が生まれます。ミクロな動きを見るアプローチというのは、試しやすいところだとコホート分析、ユーザーを属性別に切ってデータを見ること。
「この層の人にはこの機能がすごく受けているんだけど、この層の人には受けてない」ということが分かると「じゃあそれってなぜそれが起きているんだろう。ひょっとして初心者には使いづらい機能なんじゃないか」という課題を得ることができて、その対策を考えることで次の施策につながりますよね。
データドリブンのポイント④:仮説の材料はすべて吸い上げる
データドリブンの開発における仮説(アイデア)の良し悪しは、誰が出したかではなく数値で判断されます。そのため、仮説の材料は関係者全員から吸い上げられる状態を作ることが重要です。そのために使えるツールは、GitHub、Asana、DocBase、esa、Qiita:Team、Yammer、などいくらでもあります。
「モノが悪いから売れない」とは言わせない。営業マンがGitHubを使うと組織が変わる
実際にプロダクト改善を進めていくためのアイデアは、GitHubのIssueに上げるようにしています。
実際に困っていることがベースになるので、センスの無いIssueはほとんど出てきません。上がってきたIssueは、基本的に全て実装しています。結果は定量的な数値に現れるので、それを元に何が悪かったのか話をして、「じゃあこの機能は止めようか」という話になるだけのことです。
大切なのはアイデアが無視されない状況をつくることで、それによってまた次のアイデアを出そうという気持ちになることができます。このように、たとえ1%であっても改善を多く積み重ねていくことで、結果的に競争優位性を築くことにつながると考えています。
データドリブンのポイント⑤:仮説の材料を上げるためには情報共有が鍵
開発フローを回してより早く正しい解にたどり着くためには、なるべく精度の高い仮説(アイデア)を出すことが重要になります。
そのためには前線で顧客と接している営業、開発をしているエンジニア、カスタマーサポート、などすべてのメンバー間で情報共有ができており、誰もが同じ土台から仮説(アイデア)を出せることが重要になります。
「モノが悪いから売れない」とは言わせない。営業マンがGitHubを使うと組織が変わる
ただ、そもそも改善アイデアを出すためには、全員が現状を理解していることが重要です。情報の非対称性がある中でアイデアを出し、結果出てくるアイデアがしょぼかったり、既に検討済のものだと無意味ですよね。また、「それはマネージャーミーティングで話している内容です」と言われてしまうと、せっかくアイデアを出した人もテンションが下がりますし、二度とアイデアを出さなくなってしまうかもしれません。
そこでまずは情報を透明化する必要があり、そのためにQiita:Teamを使っていました。
まとめ
データドリブンで開発するためには下記のような開発フローを確立する必要があります。
- 仮説立案
- 優先順位付け
- 狙いの言語化
- 機能の実装・リリース
- 分析・解釈
また、下記の5つの重要なポイントがあります。
- プロセスが重要
- 解釈や仮説のためにユーザーテストは有効
- 解釈や仮説をデータから導くならミクロデータを見る
- 仮説の材料はすべて吸い上げる
- 仮説の材料を上げるためには情報共有が鍵
是非参考にしてみてください。