- dely株式会社
- 開発部
- 深尾 もとのぶ
1,000万DL突破!クラシルを支えるSREと、エンジニア育成術「APOLLO計画」

〜1,000万DLを突破し、急成長を続ける国内最大のレシピ動画サービス「クラシル」。そのインフラを支える、SRE育成プログラム「APOLLO計画」とは〜
Googleに始まり、FacebookやAirbnbなど、世界有数のスタートアップでも採用されている「SRE(Site Reliability Engineering)」。
サービスのインフラを支え、信頼性向上をミッションとするSREは、2015年11月にメルカリが導入したことから、日本でも近年注目を浴びている。
国内最大のレシピ動画サービス「kurashiru [クラシル] 」は、2017年12月にアプリダウンロード数1,000万を突破。
▼国内最大のレシピ動画サービス「kurashiru [クラシル] 」
同サービスを提供するdely株式会社では、急成長を続けるサービスの信頼性や安定性を高めるため、2017年1月にSREチームを発足。
同チームリーダーの深尾 もとのぶさんは、世の中にSREの知識と技術を持ったエンジニアが少ないことに、以前から課題を感じていたという。
そこで、SREを自社で育成するため、2017年8月に障害対応訓練プログラムの「APOLLO計画」を導入。
実際に発生したことのある障害を完全再現し、解決まで対応することで、SREの知識や思考法、そして嗅覚を身に付けることが出来るそうだ。
今回は、同社のSREチームのミッションから、APOLLO計画の取り組み、そしてエンジニア育成に対する考え方に至るまで、SREチームを率いる深尾さんにお話を伺った。
料理人からエンジニアへ。フリーランスを経て、クラシルに参画
僕は、delyに入社する前、ずっとフリーランスのエンジニアをしていました。
実を言うと、高校を卒業してから約8年の間は、プロの料理人として働いていたんです。その後、SIerの企業に未経験のプログラマとして入社し、そこで一通りの経験を積んだ後、30歳の時に独立しました。
フリーランスの時代は、インフラ企画やデータ分析基盤の設計など、環境構築の業務に携わってきました。その経験を生かす形で、delyにインフラエンジニアとして、2016年12月に入社しました。

delyは、日本最大のレシピ動画サービス「kurashiru [クラシル] 」を運営しています。クラシルは、「70億人に1日3回の幸せを届ける」をミッションとし、あらゆるレシピを1分間の動画でわかりやすく紹介しています。
2016年5月にサービスをローンチしたのですが、2017年12月にはアプリダウンロード数1,000万を突破しました。特に、20〜40代女性へのサービス認知度が高く、その割合は約80%に達しています。
この急成長を続けるクラシルの「インフラ」を支えるのが、僕が担当している「SRE(Site Reliability Engineering)」の仕事です。
SREチームでは、環境構築や障害対応の運用業務だけでなく、「サービスの信頼性を高めること」を主なミッションとして、Webサイトのパフォーマンス向上に日々取り組んでいます。
信頼性を高めることに上限はない。SREの3つのミッションとは
弊社SREチームのミッションは、大きく3つあります。
まず、最も重要なことは、ユーザーの方々が「当たり前にサービスを使える状態」をしっかり構築することです。
この実現のため、例えばテレビへの露出によりアクセスが集中するような時であっても、通常通りサクサク使えるように、サーバーの負荷分散などをしてサイトの「信頼性」を高める必要があります。
サーバーの死活監視には、AWS CloudWatch、Datadog、New Relic、Pingdomといったツールを活用しています。
▼「Datadog」の死活監視ツール画面
次に、ユーザー数や行動分析のデータなど、「事業判断に使うモニタリング指標をきちんと取得し、その正しさを保証する」ことも、SREの役割です。
見ているデータが正確でなければ、事業の正しい判断ができませんよね。そのため、SREが「データ欠損率を1日1%未満に抑える」といった指標を設定し、正しいデータを保証しています。
このデータ基盤は、BigQuery、Redash、Firebase、Google Analyticsを使って構築しています。
3つ目に、「エンジニア全体の生産性向上」があります。
例えば、チャットを使って、サーバーにあるデータを開発環境に反映できる仕組みを作ったり、開発フローの一部を自動化して、生産性を高める開発環境作りをしています。
ここでは、WerckerやRundeck、AWS Lambda、Hubotなどを活用していますね。
そしてこれらのミッションに対しては、「サービスレベル目標(以下、SLO:Service Level Objectives)」を据えています。

と言うのも、現実的には、僕らのミッションであるサービスの信頼性を高めることに終わりはないんですね。
サーバーの台数を増やすなど、改善すればするほど信頼性を高めることはできますが、徐々にその効果は小さくなっていき、そうすると開発側が疲弊してしまいます。
そこで、サービスの機能ごとに、そのレベルを目標とするSLOを、ユーザー目線かつ測りやすい指標で設定しています。
例えば、クラシルのメインAPIの部分では「稼働率99.99%」という数値を置いています。また、プッシュ通知であれば「毎日きちんとプッシュを送れる」という状態をSLOに設定していますね。
Googleも実践!SREを育成する、障害対応訓練プログラム
このように、重要なインフラを担うSREですが、世間一般的に、その技術を持ったエンジニアの数はまだまだ少ないんです。実際、インフラエンジニアの採用って、すごく難しいんですよ。
その背景には、プログラミングなどと比べて、インフラを教えてくれる学校のような場所がない、ということが根底の問題にあると思っていて。

その環境下で、自分自身どうやってその業務を覚えていったかと言うと、やはり現場だったんですね。
そこで、学校がない中で効率的に学ぶには、実際に業務をシミュレートするような環境があればいいな、とずっと考えていました。
そんな中、ある日GoogleのSREチームで行っている「障害対応訓練」の記事を読んだんです。そのときに「これだ!」と思いましたね。それを真似できるところは真似しようと思い、弊社にも取り入れることにしました。
具体的には、障害対応を実践的に経験できるように、クラシルで実際に発生したことのある障害を再現するプログラムを作りました。
この訓練は、NASAの「アポロ計画」にちなんで「APOLLO計画」と名付けました。
人類初の月面着陸という困難なミッションを実現させたアポロ計画のように、「SREを短期間で育成する」という大きな目標を達成したいという願いが込められています。
APOLLO計画で、障害対応の「知識、思考法、嗅覚」を学ぶ
APOLLO計画は、2017年8月に出来上がりました。そのアストロノート(参加者)第1号として、当時iOSの開発に携わってくれていた学生エンジニアの人に、実際の訓練を受けてもらいました。
この訓練において大切にしているポイントは、「知識」「事実と意見の区別」そして「障害を感知する嗅覚」の3つの習得です。

まず、コマンドやコードなどの必要知識を身に付けてもらうため、受講者は予め用意された「用語リスト」を参照して、事前学習します。
▼APOLLO計画で使われている「用語リスト」(一部)
そして、訓練開始です。第一段階としては、後に障害を再現させるための「環境構築」を自ら行います。マニュアルに従って、わからないことは質問しながら、1週間かけて作ります。
このサーバー環境が出来上がると、第二段階に移ります。ここでは、過去実際に起きた障害を再現させるプログラムを実行します。
本番環境で障害が起きたという想定で、原因特定から復旧までが任務になります。この時に大切にしているのが、「Fact(事実)とOpinion(意見)を区別して思考する」という考え方です。

例えば、CPU使用率が上がるアラートが飛んだ際に、過去の障害を元に「キャッシュが切れた」という推測をしたとします。これは、あくまで「Fact」ではなく「Opinion」です。
実際には、キャッシュが切れた可能性が本当かどうか、ログを確認しなければそれがFactであるとは言えません。
こうした行動はチーム全体を混乱させてしまう恐れがあるので、なるべくOpinionはFactに変えてから報告するようにしています。
また、後から振り返りを行えるように、「何を考え、どういう行動を取ったか」について、タイムラインにメモを残していきます。
▼実際のslack上での障害対応タイムライン
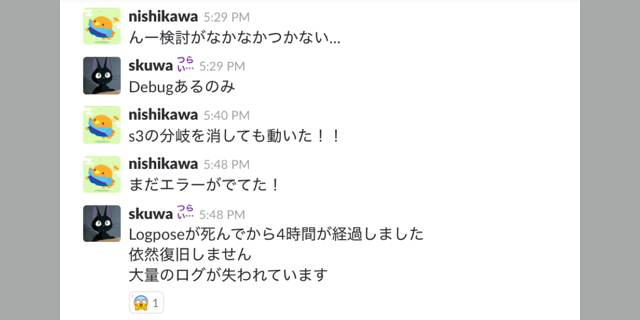
1週間にわたり、本番さながらの障害対応を経験することで、障害が起きそうな部分やボトルネックになりそうな部分を嗅ぎ分ける「嗅覚」も覚えてもらいます。
とは言え、あくまで訓練なので、実際の本番環境ですぐ実践するには難しい部分もあります。ですが、この訓練を繰り返すことで、着実にSREとしての技術を身につけることができると考えています。
Howは問わない。各エンジニアの長所を活かす、育成の仕方が大切
私は、現在チームリーダーを務めていますが、上が下をマネジメントするという考え方ではなく、各人が自分の長所を活かしながら、主体的に動ける方がいいと思っています。
よくビジネスだと「5W1H」という言葉が使われますが、その中でも「Why」と「What」だけ決めて、他は敢えて決めないという考え方をしています。
特に「How」は定めない方がいいと思っていて。と言うのも、エンジニアの場合、先輩や上司が部下のやっていることを、必ずしも全て理解できる訳ではないんですね。

そのため、Howまで決められるとすごくやりづらかったり、効率が悪くなったりして、心理的安全性を脅かしてしまう可能性だってあります。得意な言語やツールなど、その人にとって一番効率の良いやり方は、エンジニア本人にしか分からないんです。
一方で、「Why」というのは、なぜそれをやるのかという部分で非常に大事です。ここが擦り合っていないと、違う方向にアウトプットしてしまうことがあります。
なぜやるのか? が一番重要で、ここを理解していれば、その人自身が優先順位を決められると考えていて。そうすると、「When」も敢えて定める必要がなくなります。
この考え方は、APOLLO計画の「振り返り」の場面でも大切にしていますね。例えば、障害の原因特定をする際に、原因という一つの「解」に対して、どの言語でどういったツールを使ってアプローチするかといった「手法」は、本人の自由に任せています。
APOLLO計画は、まだ始まったばかりの発展途上にあるプログラムです。
今後は、今のプログラム自体も改善していきたいですし、その種類ももっと増やしていきたいですね。(了)
【読者特典・無料ダウンロード】「秒で変わるAI時代」に勝つ。最新AIツール完全攻略ガイド

近年、AI関連サービスは爆発的なスピードで進化しています。毎日のように新しいツールがリリースされる一方で、SNS上では広告色の強い情報や、過大評価されたコメントも多く見受けられます。
情報量があまりにも多く、さらにノイズも混ざる中で、「自分にとって本当に使えるツール」にたどり着くことは、簡単ではありません。だからこそ、「正しい情報源を選び、効率的にキャッチアップすること」が、これまで以上に重要になっています。
そこで今回は、SELECK編集部が日々実践している「最新AIツール情報の探し方・選び方・使い方」のノウハウに加えて、編集部が推薦する、現場で使えるAIツール22選をすべてまとめてお届けします。