
- 株式会社LIFULL
- LIFULL Lab
- 清田 陽司
8,300万のデータ資産をアルゴリズムに!LIFULL HOME’Sの、機械学習の導入法とは

〜オープンイノベーションでディープラーニングの活用を進めるLIFULL。機械学習の活用方法から、導入のコツ、外部研究者とのコラボレーションまでを紹介〜
2017年に株式会社ネクストより社名を変更し、経済産業省による「攻めのIT経営銘柄2017」にも選出された、株式会社LIFULL。
同社は昨年末に、住宅情報サイト「LIFULL HOME’S」に、ディープラーニングの技術を用いた「不整合画像検出システム」を実装した。サイト上に物件情報として登録される写真が、「キッチン」や「収納」といった定義と一致していない場合に、それを検知するシステムだ。
しかし、このようなディープラーニングの活用は、まだまだ自社で行うにはハードルが高いと感じる人も多いのではないだろうか?
実は同社は、この取り組みを自社リソースのみで行ったわけではない。LIFULL HOME’Sの物件画像8,300万枚を、「研究用データセット」として外部の研究者に無償で提供し、研究目的であれば自由に利用し、成果を発表できるようにしたのだ。
このようなオープンイノベーションの形を取ることで、技術の研究開発にかかるコストを抑え、自社サービスの品質向上を実現したのである。
今回は、同社R&D部門の清田 陽司さんと、LIFULL HOME’S上で不整合画像検出の実装をした花井 俊介さんに、ディープラーニングの活用事例や、オープンイノベーションを基軸とした研究開発プロセス、実装のポイントまで詳しく伺った。
高い精度での画像認識を可能にする、ディープラーニング
花井 僕は新卒でLIFULLに入社し、現在2年目になります。大学院の研究会でリッテルラボラトリー(現:LIFULL Lab)の発表を見て、面白そうだと思ったのがきっかけで入社しました。現在は主に住宅情報サイト「LIFULL HOME’S」のSEOを担当しています。
清田 私は10年ほど前まで、東京大学で教員をしていました。そこで産学連携企業として株式会社リッテルを立ち上げ、それが2011年に株式会社ネクスト(※現 株式会社LIFULL)に吸収合併され、今にいたります。
現在は、弊社のR&D部門となったLIFULL Labで、主に画像処理を中心とするディープラーニングの研究を行っています。また、様々な大学との共同研究を進めるなど、オープンイノベーションの推進にも携わっています。
▼左:清田さん 右:花井さん

ディープラーニングは、機械学習に使われている「ニューラルネット(※)」という技術が発展したものです。
※人間の脳が「学習する」仕組みを模倣したアルゴリズムのこと
ディープラーニングが注目されるようになったのは、2012年に行われた画像認識の競技会がきっかけです。そこで、ディープラーニングの技術を活用したチームが圧勝したのです。
そこから有用性が広く知られるようになり、今では、特に画像認識の領域で活用が進められています。
例えば製造業では、これまで人の目で判定していた不良品を、カメラで検出できるようにするといった用途などで活用されています。
8,300万ものデータから、不整合画像を自動で検出!
花井 弊社の場合は昨年末より、LIFULL HOME’Sに登録されている物件画像に、ディープラーニングの技術を活用しています。
LIFULL HOME’Sの各物件ページには、キッチン、バスルーム、収納などの画像が登録されています。これらの登録作業は基本的に、広告主である不動産会社様に行っていただくのですが、誤って居間の写真がキッチンとして登録されているなど、不整合データが散在していました。
ただ、その画像データはサービス全体で8,300万件にも上るため、全てを目視で確認することはほぼ不可能でした。
そこで、不動産会社様の登録と実際の画像が一致していない場合にそれを検知する仕組みを、ディープラーニングの技術を用いて実装したのです。R&D部門で構築された学習済みモデルがあったので、サービスの実装自体は4ヶ月ほどで完了しました。
この仕組みによって、人件費をかけずに膨大な画像データの整合性が確認できるようになりました。
▼不整合画像検出のフローと検知例

清田 このシステムの精度は、正解データを元に学習していることを前提とすれば、人間の目視とほとんど変わりません。数万枚の学習用データがあれば、かなりの精度で画像の整合性を認識できるのです。
弊社の場合には、8,300万件以上の元データを使って、アルゴリズムに学習させていきました。
花井 今回のアルゴリズムの実装を行った時点で、6,000枚以上の不整合データを発見することができました。LIFULL HOME’Sはプラットフォームサービスなので、掲載される情報の精度が上がったことは、ひとつ大きな成果かなと感じています。

データ資産を外部に提供するリスクを取ることで、研究リソースを獲得!
清田 ただ、こうしたディープラーニングの適用分野をさらに広げていくための研究開発を、自社のリソースだけで進めようとすると、年間で数十億単位の投資が必要になってしまいます。
弊社の場合、研究活動にかけられるリソースがそこまでなかったため、自分たちだけで挑戦するのは厳しいものがありました。
そのため、オープンイノベーションという選択肢を選ぶことになったのです。
そこでまずは、研究コミュニティ全体を巻き込んでいくために、研究者たちのニーズをヒアリングしていきました。すると、私たちが既に持っている物件画像を提供すれば、彼らにとっても面白い研究ができることに気が付いたのです。
結果的に私たちは、2015年から国立情報科学研究所と提携し、LIFULL HOME’Sの物件画像8,300万枚を、「研究用データセット」として無料提供することにしました。実は、先に述べた不整合画像の検出システムも、データセット提供の取り組みの副産物として生まれたものでした。
▼国立情報学研究所のホームページ上で、物件データを無料提供
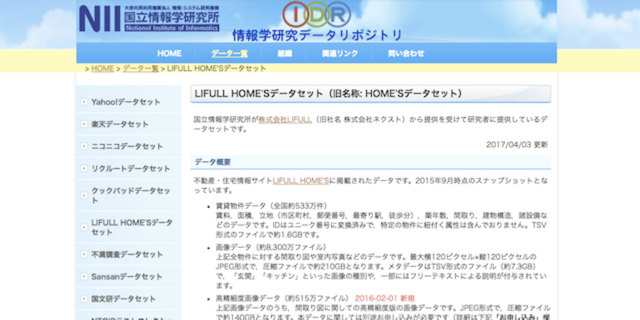
また、データだけではなく、自分たちが抱える課題もオープンにしていきました。外部の方々と話す中でも、課題をオープンにしたほうが、アイデアが生まれやすいことに気が付いたためです。
現在は、大学研究室や公的な研究機関など、約40の研究チームにデータを使っていただいています。
もちろん、自社のデータや課題をオープンにするということはリスクもあります。そうしたリスクを把握しながら、コミュニティで必要とされているものをできるだけ汲み取って、オープンイノベーションを進めています。
専門家ならではの「気付き」と「知見」を、コミュニティから得る
清田 オープンイノベーションの推進により、不整合画像の検出以外にも、新しい技術が生まれています。
こちらはまだ研究段階なのですが、セントルイス・ワシントン大学(現:サイモンフレーザー大学)で画像処理の研究をされている古川泰隆准教授が、LIFULL HOME’Sデータセットの間取り図および室内写真データを利用し、間取り図と室内写真の位置関係を対応づける技術を開発中です。
具体的には、間取り図に対応する正しい室内写真(浴室、トイレ、キッチンなど)を選ぶクイズをディープラーニングで大量に解かせることで、位置関係の正解データがなくても、写真が撮影された大まかな位置を推定できるというものです。
▼左の間取り図に対応する正しい浴室写真を4択で選ぶクイズ

(※当画像は以下の論文より引用しております。Chen Liu, Jiajun Wu, Pushmeet Kohli, Yasutaka Furukawa. Deep Multi-Modal Image Correspondence Learning. 2016. https://arxiv.org/pdf/1612.01225.pdf)
クイズの正解率は4択の場合で約7割と、人間を上回っているのですが、驚くのはその処理速度です。人間だったら大体1枚の判定に数十秒かかるものを、ディープラーニングであれば1秒で数十枚の判定が可能になります。
この技術は、正解したら報酬を与え、間違ったらペナルティーを与える「強化学習」という形で作られています。要するに、解き方を教えていなくても、大量のデータを処理させることで、間取りと写真の関係性を機械が自ら導きだしているのです。
このような学習方法が成立するという論文が出ているのですが、こうした知識は外部のチャネルを持ち合わせていないと得ることができません。
「これまでにないものを行う」サイエンスの領域では特に、コミュニティに参加し、最先端の知見をキャッチアップすることが重要になってくるのです。
アルゴリズムを作り込むより、データ整備の方が重要
清田 ディープラーニングは、精度の高いデータをある程度持っていなければ、なかなか有効に働かないということが現実問題としてあります。
これは機械学習全般の話になってくるのですが、ディープラーニングを活用するにあたっては、「データセットの整備」がとても大切です。

そういったデータの整備は、サービスを理解する人が作っていく方が良いと考えます。例えば弊社の場合、「どれがキッチンでどれが収納か」といった判断基準は、社内の人が一番良く知っているからです。
逆に、使用するアルゴリズムに関しては、オープンソースのものを使ったほうが良いと思っています。
私たちは、今回の不整合画像検出にあたって、オープンソースである「Chainer(チェイナー)」というライブラリを使っています。これは非常にシンプルで、Pythonで柔軟に変更を加えることもできます。
もちろん、自分たちでアルゴリズムを作り込めば、検出精度は上がります。しかし、ここをやりすぎると、ブラックボックス化してしまいます。オープンイノベーションという観点でも、あまり好ましくありません。
会社にとっての真の資産であるデータセットにこそ、注力すべきだと思っています。
人生の大きな選択を、サイエンスでサポートしていきたい
清田 弊社は不動産情報サービスだけではなく、介護や保険領域など、人生の大きな選択に関わるサービスを多岐に展開しています。
例えば「家を買う」となると、その選択は10年、20年後の人生まで左右しますよね。そういった、人生の重要な選択を支えるサイエンスは、まだあまりないと思っています。
今後はデータを活用し、10年後、20年後の見通しを提示するといったことで、ユーザーさんがより良い人生の選択ができるような仕組みづくりに挑戦していきたいと思います。
花井 僕も、LIFULL HOME’Sの物件情報をより質の高いものにすることで、ユーザーさんが最適な選択ができるようにしていきたいですね。
実際、写りの良い写真が多い物件の方が、住みたい人が多かったというデータもあります。これからも、画像のクオリティを上げたり、パノラマ画像の不整合検知を行ったりといった取り組みで、ユーザーさんに満足してもらえるプラットフォームを作っていきたいと思います。(了)








