- 株式会社SmartHR
- 取締役 CTO
- 佐藤 大資
稼働率「99.9999%」を実現する!Webサービスを安定運用させる、SREチームとは

〜Webサービスのスケールに欠かせない、安定性と信頼性。従業員10,000人規模のクライアントでも対応できるサービス水準を目指す、SmartHR「SREチーム」とは〜
Webサービスは拡大するにつれ、次第に安定性や信頼性といった「品質」を、ユーザーに求められるようになる。
だが、機能開発を行いながらサービスを安定運用させようとすると、どうしても後者は後回しになってしまいがちである。
いまや4,800社以上の企業で使用される、クラウド労務ソフト「SmartHR」を開発する、株式会社SmartHR。
同社は、導入企業が「10,000人」規模を越えたタイミングで、サービス水準の向上を目的とした専門のエンジニア部隊「SREチーム」を発足した。(※SRE:Site Reliability Engineering)
同チームでは、3人のエンジニアメンバーが100%のリソースを費やし、稼働率の改善やインシデント管理を行っている。そして、発足からたった4ヶ月で、サーバー状態の大幅改善にも成功したそうだ。
今回はSREチームを発足した同社CTOの佐藤 大資さんに、SREチームの役割から、サービス水準を向上させるための具体的なプロセス、実際に使用しているツールまで、詳しく伺った。
サービス水準の向上に注力するため、「SRE」チームを発足
僕は2015年の7月、SmartHRが立ち上がって半年後くらいに弊社にジョインしました。現在はCTOとして、開発全般に携わっています。
SmartHRは、入・退社時に発生する社会保険や年末調整といった労務手続きを自動化する、クラウド労務ソフトです。現在、立ち上げから1年8ヶ月で、約4,800社の企業様にご登録いただいています。
この成長にともなって、大企業様の導入割合も増えたことで、サービスに高い安定性や信頼性が求められるようになってきました。

以前はシステムの安定化を、新機能の実装や改善と並列で行ってきました。でも、全員で機能開発をしていると、サービスを安定運用させるための開発は、どうしても後回しになっていました。
そこで2017年1月より、サービス水準の向上を目標としてシステム改善に取り組む「SRE(Site Reliability Engineering)チーム」を発足しました。
弊社では8人のエンジニアがいるのですが、そのうち3人はこのチームに所属し、100%のリソースを費やしています。
SREチームの最初の一歩は、モニタリングのための環境づくり
SREチームが目指しているのは、従業員10,000人規模の企業にもスムーズに使っていただけるサービス水準を実現することです。
例えばサービス稼働率で言うと、99.9999%を目指しています。この数値は、SaaSを開発している場合に、目指すべき絶対目標です。

SREチームを発足してサービス水準の向上に本格的に取り組むようになってから、この稼働率も徐々に改善してきました。
例えばAWSのEnvironment Healthを見ると、今年の1月から「警告」の数が減ってきているのがわかります。最終的にはこの警告をなくし、フラットな状態に安定化させるのが理想です。
▼AWSのEnvironment Healthのグラフ
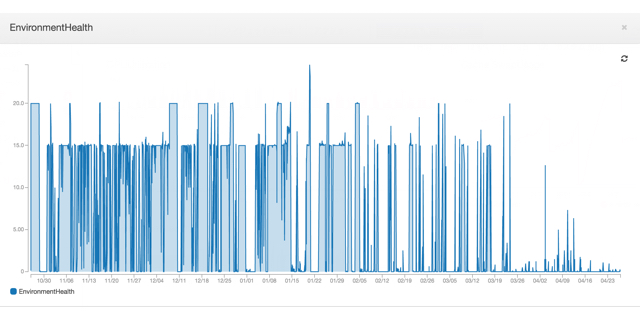
とは言え、今はまだ立ち上げの段階なので、数値や障害をしっかりとモニタリングするための環境づくりに注力しています。実際に行ったのは、稼働率のモニタリングとインシデント管理のための環境整備です。
死活監視とE2Eテストに外部ツールを活用し、自動化を促進
まず稼働率については、「Pingdom」と「New Relic Synthetics」を使って監視・テストを行っています。
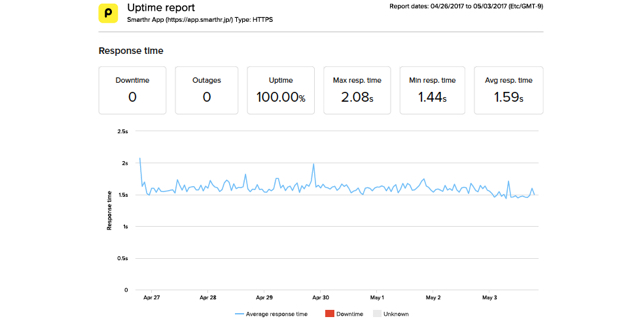
まずPingdomですが、これはWebサービスの死活監視ができるサービスです。
弊社では無料プランを使っていて、レスポンスタイムや障害、サーバの監視を行っています。各数値がしきい値を超えた場合に、アラートが出る仕組みとなっています。
▼Pingdomの画面
そしてNew Relic Syntheticsは、ローカルでE2Eテスト(※Webブラウザ上での、エンドユーザー視点でのテスト)ができる環境を作るために使っています。
また、New Relic SyntheticsのScripted Browserという機能を使うと、画面遷移を含めたテストが自動で実行できます。いくつものパターンの動作確認を手動でしなくても、自動でWebの遷移を実行し、その結果を計測してくれるんです。
自動化できない部分であっても、内部にはSeleniumが使われているので、JavaScriptで皆が簡単にテストを書くことができます。
▼E2Eテストを行っている様子

さらに、テストに失敗した場合は、自動でスクリーンショットを撮ってくれるため、どこに障害が発生しているかがすぐにわかるようになっています。
インシデントは、エンジニア以外も登録できるようTrelloで管理
次にインシデント管理ですが、インシデント管理に特化したツールは特に使わずに、タスク管理ツールの「Trello」を活用しています。
▼Trelloの障害対応用ボード(左から、発生・対応中・復旧・再発防止策検討中・完了)
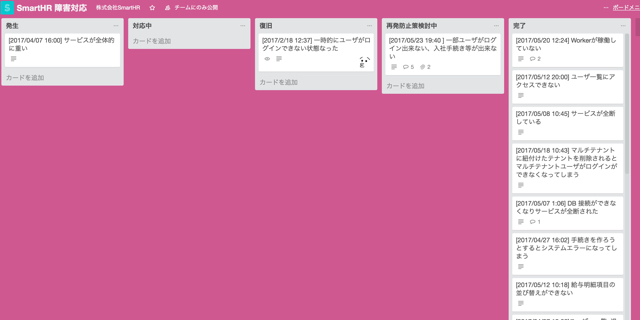
Trelloの良さは、エンジニアでなくても使いやすいUIなので、障害が起きた場合に誰でもタスクを登録できることです。
障害が発生したら、「Qiita」上にドキュメント化されたインシデント管理のルールに沿って、タスクをTrelloに追加してもらうようにしています。
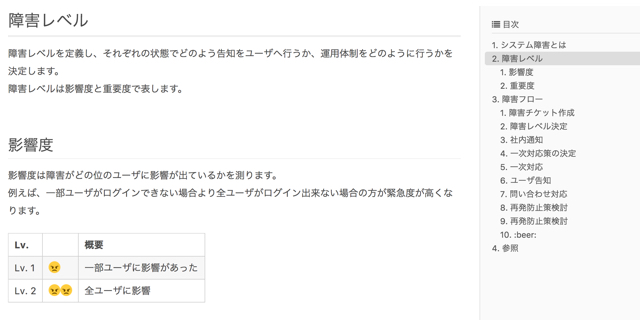
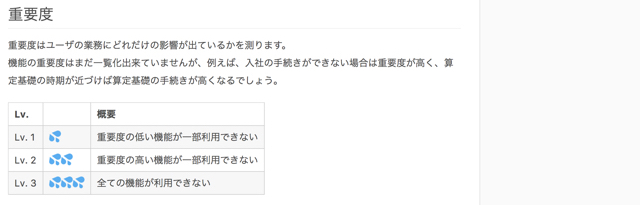
タスクを追加するときには、その障害の「影響度」と「重要度」を、それぞれ登録してもらっています。こうすることで、複数のインシデントが発生した際にも、優先度が明確になります。
▼Qiita上にまとめられたインシデント管理のルール
この仕組みにより、障害などをすぐさま検知し、対応できるようになっています。Trelloにカードが追加されるとSlackにも通知が来るので、気が付いた人がすぐに一次対応できます。
▼Slack上でbot「障害発生くん」がアラートを飛ばしている様子
その場の対処だけでなく、自動で改善する「仕組み」も作る
このように、サービス水準を向上させるためのサイクルを回す一方で、SREチームでもうひとつ重要な業務があります。それが、開発の効率化です。
例えば障害が発生してサーバーが壊れた場合には、そこを修復するだけでなく、自動で修復してくれるような仕組みを作るようにしています。
こうして自動化を徹底することで、人的時間の削減に繋がったり、担当するエンジニアが他の開発業務に携われたり、オンコールエンジニアリングをする機会を減らすことができます。

また、サービス水準において重要なカスタマーサクセスにおいても、効率化できるところはSREチームが動いています。
例えば、お客様から「従業員が増えたのでプランを変更したい」という要望があったとします。
この場合、従来だとコンソール上でエンジニアが行わなければいけなかった作業を、オペレーターの方が管理画面上で操作できる仕組みを作ったりしています。
SREチームのあるべき姿を模索しつつ、ユーザー体験を上げていく
僕たちの場合は、導入先の企業様が1,000人規模になった時に、安定性や信頼性をより重視していこう、という流れになりました。
それまでは、サービスを止めることなくアップデートを行うことを目標に開発を行ってきました。そしてこれからは、安定的な運用ができるまで、ユーザーの皆さまの業務に支障のない時間帯に、一時的にサービスを停止してアップデートを行うことにしました。
ただし、この対応は一時的なものとして、安定的なアップデート体制が整った際には、本来の「サービスを止めることなくアップデートを行う」という方針に戻すことを目標にしています。

とは言え、スタートアップの初期段階においては、やはり新機能の開発をスピーディーに進めることの方が大切になると思っています。
SREって、なかなか新しい組織だと思います。最先端の企業がチャレンジしてるとは思うんですけど、まだしっかりとした仕組みを定義できているわけではないと思います。
なので我々も模索しながら、SREという組織をどうしていくべきかを考えていきたいです。
弊社のSREチームは今のところ3名ですが、今年いっぱいで6人以上のチームにしていきたいと思っています。自律したエンジニアに仲間になってもらって、自律的に発展し、スケールしていけるような組織作りをしたいです。
そうして、ユーザー体験を良くすることに注力して、SmartHRを多くの人々により安心して使ってもらえるサービスにしていきたいです。(了)